Updated 13 February 2024 v3.6
Content, schedule and panelists are all subject to change.
Monday 12 February 2024 – Day 1
Panel 1 – DATA SOVEREIGNTY – OPEN DATA
Topics
- Data Sovereignty and Open Data – mutually exclusive?
- Risks and opportunities of GenAI.
- Indigenous Science – implications for the debates about data.
- What next for Aotearoa New Zealand.
Questions
- Where do you sit on the Data Sovereignty/Open Data debate?
- Shifting from data to knowledge – what ways do we have to enable the protection and sharing of indigenous collective knowledge (e.g. Mātauranga Māori in New Zealand)?
- What is happening here and internationally to support conversations to occur that might enable wellbeing?
Moderator: Vicki Compton
Panelists (link to Bio)






Tuesday 13 February 2024 – Day 2
Panel 2 – IS APPLICATION PERFORMANCE TUNING STILL NECESSARY?
Q1 – Hardware continues to get faster, so why bother about performance?
Instead of spending a fortune on tuning the application(s), the money is better spent buying new processors and systems, or just expand the usage of cloud based systems. This is easiest and provides a continuous performance improvement as the hardware evolves.
Q2 – System software is getting better too, so why should we care about performance?
Software has gotten so smart, why care about performance any longer? For example, compiler technology has evolved tremendously and there are many highly optimized libraries to leverage. DSLs (Domain Specific Languages) also boost performance and productivity. On the OS side, schedulers are ever getting smarter too.
Q3 – If it ain’t broken, don’t fix it! Why bother tuning a legacy application?
Human resources are scarce and expensive. Nobody really understands these legacy applications anyhow, so tuning them is a huge money drain without a clear benefit.
Q4 – AI comes to the rescue here too! The AI system will learn how to improve the performance!
AI is evolving so rapidly now. It can be trained on performance and make decisions on tuning the applications. With that knowledge, AI is able write new and more efficient code. By automating this, application tuning becomes a blackbox in the workflow.
Moderator: Nicolás Erdödy.
Panelists:







Wednesday 14 February 2024 – Day 3
Panel 3 – CONTINUOUS COMPUTING
From the Edge to the hyperscale data center and vice-versa. Cybersecurity by design.
Topics:
- Seamless Integration across the Computing Spectrum: The convergence of edge computing and hyperscale data centers to enable real-time, efficient data processing and analysis.
- Cybersecurity as a Core Feature: Designing systems and networks with security built-in from the ground up, rather than as an afterthought.
- Scalability and Flexibility Challenges: Adapting infrastructure to handle dynamic workloads with varying demands on computing power and data storage.
- Energy Efficiency and Sustainability: Innovations in computing that reduce energy consumption and carbon footprint across the entire computing continuum.
- Distributed Computing for Resilience: The role of decentralized architectures in enhancing system robustness and reliability.
- Advanced Algorithms and Models: Leveraging AI and machine learning for predictive analytics, anomaly detection, and automated system optimization.
- Regulatory and Ethical Considerations: Navigating the complex landscape of data privacy, sovereignty, and ethical use of computing resources.
Questions:
- How can continuous computing models bridge the gap between edge devices and hyperscale data centers to enable more cohesive and real-time data analytics?
- In the context of ‘cybersecurity by design,’ what are the primary challenges and solutions for integrating robust security measures throughout the computing continuum?
- What strategies can be employed to ensure that the scalability and flexibility of computing infrastructures do not compromise security or operational efficiency?
- As we strive for more energy-efficient computing models, what innovations are on the horizon for reducing the environmental impact of both edge computing and hyperscale data centers?
- How can collaborations between academia, industry, and government accelerate the advancement of continuous computing technologies and cybersecurity measures?
- How can distributed computing architectures contribute to the resilience and reliability of the computing continuum, particularly in the face of cyber threats?
- In leveraging AI and machine learning across the computing spectrum, what ethical considerations must be taken into account to ensure responsible use of technology?
- Given the increasing importance of data privacy and sovereignty, how can continuous computing models adapt to comply with global regulatory requirements while still achieving optimal performance?
Moderator: Nicolás Erdödy.
Panelists:





Thursday 15 February 2024 – Day 4
Panel 4 – THE FUTURE OF COMPUTING
When enough is enough? Do we need exascale and beyond?
“Investment in supercomputing and related HPC technologies is not just a sign of how much we are willing to bet on the future with someone else’s money, but how much we believe in it ourselves, and more importantly, how much we believe in the core idea that we can predict and therefore shape the future of the world” (*)
“The best HPC systems in the world can only simulate a rude approximation of anything for a reasonably long term, or a high fidelity approximation for a very short term, measured in picoseconds to seconds depending on what it is. We just don’t have enough compute to really simulate at the necessary scale”. Can we afford it?
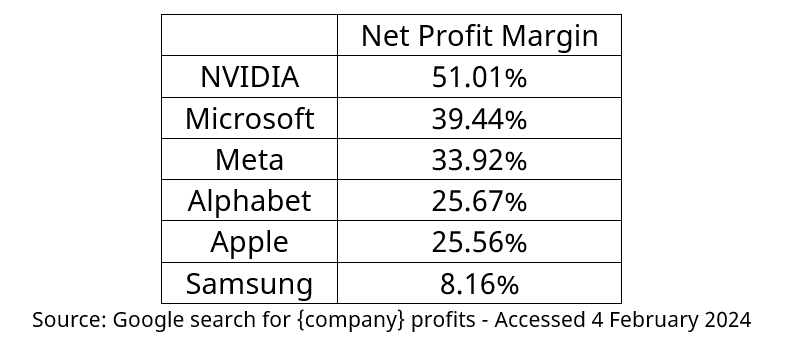
“The rise of the hyperscalers and generative AI based on the personal information culled from billions of people and untold zillions of interactions between us and our retailers, our governments, our schools, and every other kind of imaginable telemetry”, created “new winners” (check table) and is challenging what is strategic long-term R&D and where it should be going.
Do you think that the world is taking HPC as seriously as it needs to if we are to solve some pretty big problems?
HPC isn’t a hugely profitable business -should it be?
Are governments, taxpayers, society at large being more and more disconnected about technological and scientific advance? Who’s filling the gap?
Which technologies are essential to make the Future of Computing “feasible”?
In 2023, TSMC became the world’s biggest #semiconductor maker by revenue, topping Intel and Samsung Electronics for the 1st time.
2023 Revenue in US dollars
TSMC: $69.30 billion
Intel: $54.23 billion
Samsung (chip division): $50.99 billion
Thread 1/9 $TSM $INTC #Samsung pic.twitter.com/FUqm6xha5O
How is power consumption, access to raw materials & resources, supply chain issues, government restrictions, globalisation changes going to influence roadmaps? Is realistic to aim beyond exascale?
Moderator: Nicolás Erdödy
Panelists:




(*) Paragraphs taken from The Next Platform article “The future we simulate is the one we create” (Recommended reading) https://www.nextplatform.com/2024/01/06/the-future-we-simulate-is-the-one-we-create/ with personal written permission from the author, Timothy Prickett Morgan -co-editor of The Next Platform.

PANELS FROM MULTICORE WORLD 2023
Panel 1: “Agriculture Empowered by Supercomputing”
Monday 13 February 2023 Day 1
- Agriculture: from the less digitised industry to next-gen computing applications.
- What for? How?
- Open source software and hardware.
- Reliable and fault tolerant peer-to-peer platforms.
- How many ecosystems? (e.g. mineral.ai, etc).
Questions:
In the USA, farm output contributes about 0.7% of GDP and the full contribution from agriculture, food, and related industries is about 5.4% of GDP. For purposes of comparison, the IT industry contributes more than 10% of GDP.
Might we thus find ourselves with digital twins, data centres everywhere, and AI always, but not enough food?
Let’s reverse this: if the IT industry is so “powerful” then couldn’t it be the “salvation” for the agriculture and related sectors?
What about if that 5.4% of GDP is a consequence of massive inefficiencies through the whole value chain and supply chain (35%-50% of food harvested/produced never reaches the consumer, unbalanced prices and costs between farm gate and consumer, etc.)?
Would that be an hypothesis of interest?
Instead of increasing production, what about optimisation, efficiency, input reduction, etc? Enter consequences for the climate, too.
And where are we -this community, going to help?





Panel 2: “Modelling, Simulations and Digital Twins”
Tuesday 14 February 2023 Day 2
- Digital Distributed Manufacturing.
- Open Platforms vs {meta, omni,…} verses. AR/VR.
- Supply chain challenges, scalability, interdependency.
- Business and industry challenges.
- Software and Systems for the Enterprise in a Complex World.
Some quotes:
According to eminent statistician George Box, “All models are wrong, but some are useful”.
“The only difference between theory and practice is that in theory they are the same.”
Perhaps the same is true of simulation and reality.
Since the 1960’s the potentials of software modelling, especially system dynamics modelling and simulation – and ‘digital twins’ – have attracted attention. Arguably, they could be viewed as specious solutions searching for soluble problems.
The real world is filled with wicked problems – and super-wicked problems.
What are the constraints on algorithmic and non-algorithmic computer-based modelling and simulation of real world challenges and opportunities?



Panel 3: “Exascale to the Edge”
Wednesday 15 February 2023 Day 3
- Distributed Heterogeneous Computing.
- Small – Cheap – Fast – Secure – Scalable.
- Trusted computing.
- Network challenges.
- Where’s my data? When every device becomes a Data-Centre.
Thanks to advances in hardware processing power, in terms of both energy and hardware costs, it can now be relatively cheaper to process data near its source rather than transport it to a central processing facility.
Meanwhile, network management paradigms continue to evolve towards automated, relatively light human touch (and therefore lower cost and more reliable) architectures.
What are the likely future trajectories of the trade-offs between distributed data processing with lower transport requirements and costs; and centralised data processing with relatively higher transport requirements and costs?
How might these potential scenarios impact New Zealand as a relatively remote location, yet with an abundance of renewable energy sources?
What can we do to get exascale results with petascale cost and environmental impact?
a. “Back to the 1970s” focus on software efficiency?
b. Algorithms research?
c. Continued hardware improvements? Efficiency?
Special-purpose hardware accelerators?
“Exascale to the edge” might suggest pushing the computational burden to smartphones and similar devices. If so…
a. Will users accept corresponding reductions in battery
lifetime?
b. How to motivate deployment of needed special-purpose
hardware accelerators to the client devices?
c. How to ensure that data-locality laws are also respected?
(If one leaves a country carrying a smartphone containing data that must remain in that country, is that a
violation, and if so, how is it to be enforced? And how does one know that one’s smartphone contains
such data?)
d. To what extent are the results of client-device computations trusted, given that such devices might well
have been compromised? (People really did attempt to spoof SETI@Home!)
What is the overall tradeoff between longer-lived hardware on the one hand and more-rapid deployment of improved hardware on the other?
What are the tradeoffs between the software efficiencies that can be more easily attained across a uniform compute base and th advantages of exploiting a larger group of non-uniform systems?
What is the failure model for computations spanning multiple client devices? For example, SETI@Home used redundant computations.



Panel 4: “AI, of course!”
Thursday 16 February 2023 Day 4
- Challenges in compute power, networks, HW, SW.
- Generative AI (should I ask ChatGPT to write my abstract?)
- Huge Graph Neural Networks.
- Data sovereignty vs Colonisation.
Is AI really useful for you? How? Orders of magnitude?
Who are you depending on? Vendor? Legacy? How much?
What do you need/want next from AI?
What are you worried about?
Ethics? Cost? Inaccuracies? Inconsistencies? Black boxes? Black Swans?






